從數據到智慧 詳解大廠知識圖譜構建全流程與NLP核心技術
在當今信息爆炸的時代,如何從海量、異構、非結構化的數據中提取出結構化知識,并構建能夠理解、推理和應用這些知識的系統,已成為人工智能領域的核心挑戰之一。知識圖譜(Knowledge Graph)作為一種以圖結構形式表示實體、概念及其相互關系的語義網絡,正成為各大科技公司(“大廠”)在搜索、推薦、問答、風控等核心業務中不可或缺的底層基礎設施。本文將從技術實現視角,深入剖析大廠構建知識圖譜的全流程,并重點解析其中涉及的自然語言處理(NLP)與計算機軟件及網絡技術。
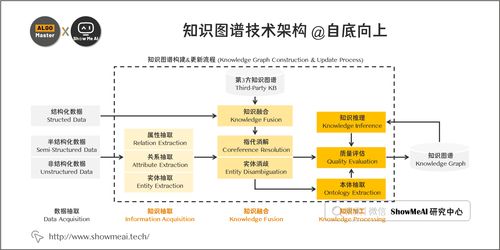
一、知識圖譜構建全流程:一個系統化工程
大廠構建知識圖譜并非一蹴而就,而是一個融合了數據工程、算法研發和系統工程的復雜閉環流程。其核心階段通常包括:
1. 知識建模與本體構建:
這是藍圖設計階段。首先需要定義知識圖譜的“骨架”——本體(Ontology)。本體明確了知識圖譜中的核心概念(實體類型,如“人物”、“公司”、“產品”)、概念間的層級關系(如“蘋果公司”是“科技公司”的子類)、以及實體間的屬性與關系(如“創立于”、“是CEO”)。大廠通常會結合業務需求(如電商領域需要“商品”、“品牌”等實體)與行業標準(如Schema.org)來設計本體,確保知識的可擴展性和一致性。
2. 知識獲取:多源異構數據融合:
這是“原材料”收集階段。數據源極其廣泛,包括:
- 內部結構化數據:如業務數據庫中的用戶表、商品表、交易記錄。
- 半結構化數據:如網頁表格、JSON/XML格式的API數據。
- 非結構化文本數據:如新聞、社交媒體內容、產品描述、客服日志,這是NLP技術的主戰場。
* 外部知識庫:如維基百科、領域專業數據庫。
技術挑戰在于數據的清洗、對齊和融合,需要強大的數據管道(Data Pipeline)支持。
3. 知識抽取:NLP技術的核心應用:
這是從非結構化文本中“煉金”的關鍵步驟,主要依賴NLP技術:
- 命名實體識別(NER):識別文本中屬于預定義類別的實體,如人名、地名、組織名、產品名等。大廠通常采用基于深度學習的模型(如BERT、RoBERTa及其變體),并結合領域數據進行微調,以達到極高的準確率和召回率。
- 關系抽取(RE):識別文本中兩個實體之間的語義關系,如“馬云 創立了 阿里巴巴”中的“創立”關系。方法從早期的模式匹配發展到基于深度學習(序列標注、閱讀理解范式)的端到端模型。
- 屬性抽取:抽取實體的屬性信息,如人物的出生日期、公司的所在地。
- 事件抽取:識別文本中發生的事件、事件的參與角色及時間地點等要素,對理解動態知識尤為重要。
4. 知識融合與對齊:
來自不同數據源的同一實體(如“阿里巴巴”、“Alibaba Group”)可能存在不同表述或冗余信息。此階段旨在消除歧義、合并沖突、建立統一視圖。關鍵技術包括:
- 實體鏈接:將文本中提到的實體指稱(如“蘋果”)鏈接到知識圖譜中唯一的實體ID(是“蘋果公司”還是“水果蘋果”)。
- 知識消歧:解決同名實體(如“李娜”是歌手還是網球運動員)的歧義問題。
- 數據融合:對不同來源的同一實體的屬性值進行沖突檢測與擇優合并。
5. 知識存儲與計算:
經過處理的知識需要被高效存儲和查詢。圖數據庫(如Neo4j, JanusGraph, Nebula Graph)因其對圖結構數據的原生支持,成為存儲知識圖譜的熱門選擇。大廠也常根據規模(如百億級三元組)和性能需求,自研分布式圖存儲與計算系統(如阿里巴巴的GraphScope,百度的PGL),結合圖計算引擎(如Spark GraphX)進行大規模圖分析(如社區發現、影響力傳播)。
6. 知識推理與應用:
構建圖譜的最終目的是應用。基于已有的知識,可以通過規則推理(如定義“配偶關系的對稱性”)或嵌入表示學習(將實體和關系映射到低維向量空間,通過向量運算如TransE進行推理)來發現隱含知識,補全圖譜。知識圖譜最終賦能上層應用,例如:
- 搜索引擎:提供精準的實體卡片和關聯搜索。
- 智能問答:直接回答關于實體的事實性問題。
- 個性化推薦:利用用戶、商品、內容間的復雜關系網絡進行精準推薦。
- 風險控制:通過企業股權關系、個人社交關系圖譜識別欺詐團伙。
二、支撐技術棧:軟件與網絡技術的融合
一個工業級知識圖譜系統的背后,是一套堅實的技術棧:
- 分布式計算與存儲:處理海量數據離不開Hadoop、Spark、Flink等大數據框架,以及HBase、Hive等分布式存儲系統,確保數據處理的吞吐量和可擴展性。
- 微服務與容器化:知識圖譜的構建和更新流程通常被拆分為多個獨立的微服務(如NER服務、關系抽取服務、實體鏈接服務),通過Docker容器化部署,利用Kubernetes進行編排管理,實現敏捷開發和高可用性。
- 流批一體處理:支持離線批量構建全量圖譜(批處理)和實時處理流式數據(如新聞流)以增量更新圖譜(流處理)。
- 高性能網絡與RPC框架:微服務間的高效通信依賴高性能網絡基礎設施和RPC框架(如gRPC),保證低延遲的數據傳輸。
- 模型服務化(Model Serving):將訓練好的NLP模型(如抽取模型)封裝為可擴展的在線服務(常用TensorFlow Serving、TorchServe等),供構建流水線實時調用。
三、挑戰與趨勢
盡管技術日趨成熟,大廠在構建知識圖譜時仍面臨諸多挑戰:自動化程度仍需提高(減少人工干預)、多模態知識融合(結合圖像、視頻中的知識)、動態知識更新(實時捕捉世界變化)、以及可解釋性與可信賴性。知識圖譜將與大規模預訓練語言模型(如GPT系列)深度融合,形成“大模型+知識圖譜”的雙輪驅動,讓機器不僅擁有從數據中學習模式的能力,也具備結構化的知識記憶與推理能力,向更通用的人工智能邁進。
知識圖譜的構建是一個集NLP、數據工程、圖計算、分布式系統于一體的綜合性系統工程。大廠通過系統化的流程設計和強大的技術棧,將散落的數據轉化為互聯的智慧,為智能應用的落地提供了堅實的知識基石。
如若轉載,請注明出處:http://www.youyoucha.cn/product/56.html
更新時間:2026-01-06 09:12:30